🔄 Distribution-Aware Encoding
Distribution-Aware Encoding
Automatically detect and handle various data distributions for optimal preprocessing.
📋 Overview
The Distribution-Aware Encoder is a powerful preprocessing layer that automatically detects and handles various data distributions. It intelligently transforms your data while preserving its statistical properties, leading to better model performance.
Automatic Distribution Detection
Identifies data patterns using statistical analysis
Smart Transformations
Applies distribution-specific preprocessing
Production-Ready
Built with pure TensorFlow operations for deployment
Flexible Integration
Works seamlessly with KDP's preprocessing pipeline
Graph Mode Compatible
Works in both eager and graph execution modes
Memory Efficient
Optimized for large-scale datasets
🎯 Use Cases
Financial Data
Handling heavy-tailed distributions in price movements
Sensor Data
Processing periodic patterns in time series
User Behavior
Managing sparse data with many zeros
Natural Phenomena
Handling multimodal distributions
Count Data
Processing discrete and zero-inflated distributions
🚀 Getting Started
Basic Usage
from kdp import PreprocessingModel, FeatureType
# Define numerical features
features_specs = {
"price": FeatureType.FLOAT_NORMALIZED,
"volume": FeatureType.FLOAT_RESCALED,
"rating": FeatureType.FLOAT_NORMALIZED
}
# Initialize model with distribution-aware encoding
preprocessor = PreprocessingModel(
path_data="data/my_data.csv",
features_specs=features_specs,
use_distribution_aware=True, # Enable distribution-aware encoding
distribution_aware_bins=1000 # Number of bins for distribution analysis
)
Advanced Configuration
from kdp.features import NumericalFeature
from kdp.layers.distribution_aware_encoder_layer import DistributionType
features_specs = {
"price": NumericalFeature(
name="price",
feature_type=FeatureType.FLOAT_NORMALIZED,
preferred_distribution=DistributionType.LOG_NORMAL # Specify distribution
),
"volume": NumericalFeature(
name="volume",
feature_type=FeatureType.FLOAT_RESCALED,
preferred_distribution=DistributionType.ZERO_INFLATED # Handle sparse data
)
}
preprocessor = PreprocessingModel(
path_data="data/my_data.csv",
features_specs=features_specs,
use_distribution_aware=True,
distribution_aware_bins=1000,
detect_periodicity=True, # Enable periodic pattern detection
handle_sparsity=True # Enable sparse data handling
)
📊 Supported Distributions
| Distribution Type | Description | Detection Criteria | Use Case |
|---|---|---|---|
| Normal | Standard bell curve | Skewness < 0.5, Kurtosis ≈ 3.0 | Height, weight measurements |
| Heavy-Tailed | Longer tails than normal | Kurtosis > 4.0 | Financial returns |
| Multimodal | Multiple peaks | Multiple histogram peaks | Mixed populations |
| Uniform | Even distribution | Bounded between 0 and 1 | Random sampling |
| Exponential | Exponential decay | Positive values, skewness > 1.0 | Time between events |
| Log-Normal | Normal after log transform | Positive values, skewness > 2.0 | Income distribution |
| Discrete | Finite distinct values | Low unique value ratio (< 0.1) | Count data |
| Periodic | Cyclic patterns | Significant autocorrelation | Seasonal data |
| Sparse | Many zeros | Zero ratio > 0.5 | User activity data |
| Beta | Bounded with shape parameters | Bounded [0,1], skewness > 0.5 | Proportions |
| Gamma | Positive, right-skewed | Positive values, mild skewness | Waiting times |
| Poisson | Count data | Discrete positive values | Event counts |
| Cauchy | Extremely heavy-tailed | Very high kurtosis (> 10.0) | Extreme events |
| Zero-Inflated | Excess zeros | Moderate zero ratio (0.3-0.5) | Rare events |
| Bounded | Known bounds | Explicit bounds provided | Physical measurements |
| Ordinal | Ordered categories | Discrete ordered values | Ratings, scores |
⚙️ Configuration Options
| Parameter | Type | Default | Description |
|---|---|---|---|
use_distribution_aware |
bool | False | Enable distribution-aware encoding |
distribution_aware_bins |
int | 1000 | Number of bins for distribution analysis |
detect_periodicity |
bool | True | Detect and handle periodic patterns |
handle_sparsity |
bool | True | Special handling for sparse data |
embedding_dim |
int | None | Output dimension for feature projection |
add_distribution_embedding |
bool | False | Add learned distribution type embedding |
epsilon |
float | 1e-6 | Small value to prevent numerical issues |
transform_type |
str | "auto" | Type of transformation to apply |
🎯 Best Practices
Distribution Detection
- Start with automatic detection
- Specify preferred distributions only when confident
- Use appropriate bin sizes for your data scale
- Monitor detection accuracy with known distributions
Performance Optimization
- Enable periodic detection for time series data
- Use sparse handling for data with many zeros
- Consider memory usage with large bin sizes
- Use appropriate embedding dimensions
Integration Tips
- Combine with other KDP features for best results
- Use appropriate feature types (FLOAT_NORMALIZED, FLOAT_RESCALED)
- Monitor model performance with different configurations
- Consider using distribution embeddings for complex patterns
🔍 Examples
Financial Data Processing
from kdp import PreprocessingModel, FeatureType
from kdp.features import NumericalFeature
from kdp.layers.distribution_aware_encoder_layer import DistributionType
# Define financial features
features_specs = {
"price": NumericalFeature(
name="price",
feature_type=FeatureType.FLOAT_NORMALIZED,
preferred_distribution=DistributionType.LOG_NORMAL
),
"volume": NumericalFeature(
name="volume",
feature_type=FeatureType.FLOAT_RESCALED,
preferred_distribution=DistributionType.ZERO_INFLATED
),
"volatility": NumericalFeature(
name="volatility",
feature_type=FeatureType.FLOAT_NORMALIZED,
preferred_distribution=DistributionType.CAUCHY
)
}
# Create preprocessing model
preprocessor = PreprocessingModel(
path_data="data/financial_data.csv",
features_specs=features_specs,
use_distribution_aware=True,
distribution_aware_bins=1000,
detect_periodicity=True, # For daily/weekly patterns
handle_sparsity=True, # For low-volume periods
embedding_dim=32, # Project to fixed dimension
add_distribution_embedding=True # Add distribution information
)
Sensor Data Processing
features_specs = {
"temperature": NumericalFeature(
name="temperature",
feature_type=FeatureType.FLOAT_NORMALIZED,
preferred_distribution=DistributionType.NORMAL
),
"humidity": NumericalFeature(
name="humidity",
feature_type=FeatureType.FLOAT_NORMALIZED,
preferred_distribution=DistributionType.BETA # Bounded between 0-100%
),
"pressure": NumericalFeature(
name="pressure",
feature_type=FeatureType.FLOAT_NORMALIZED,
preferred_distribution=DistributionType.NORMAL
)
}
preprocessor = PreprocessingModel(
path_data="data/sensor_data.csv",
features_specs=features_specs,
use_distribution_aware=True,
distribution_aware_bins=500, # Fewer bins for simpler distributions
detect_periodicity=True, # For daily temperature cycles
handle_sparsity=False, # No sparse data expected
embedding_dim=16 # Smaller embedding for simpler patterns
)
📊 Model Architecture
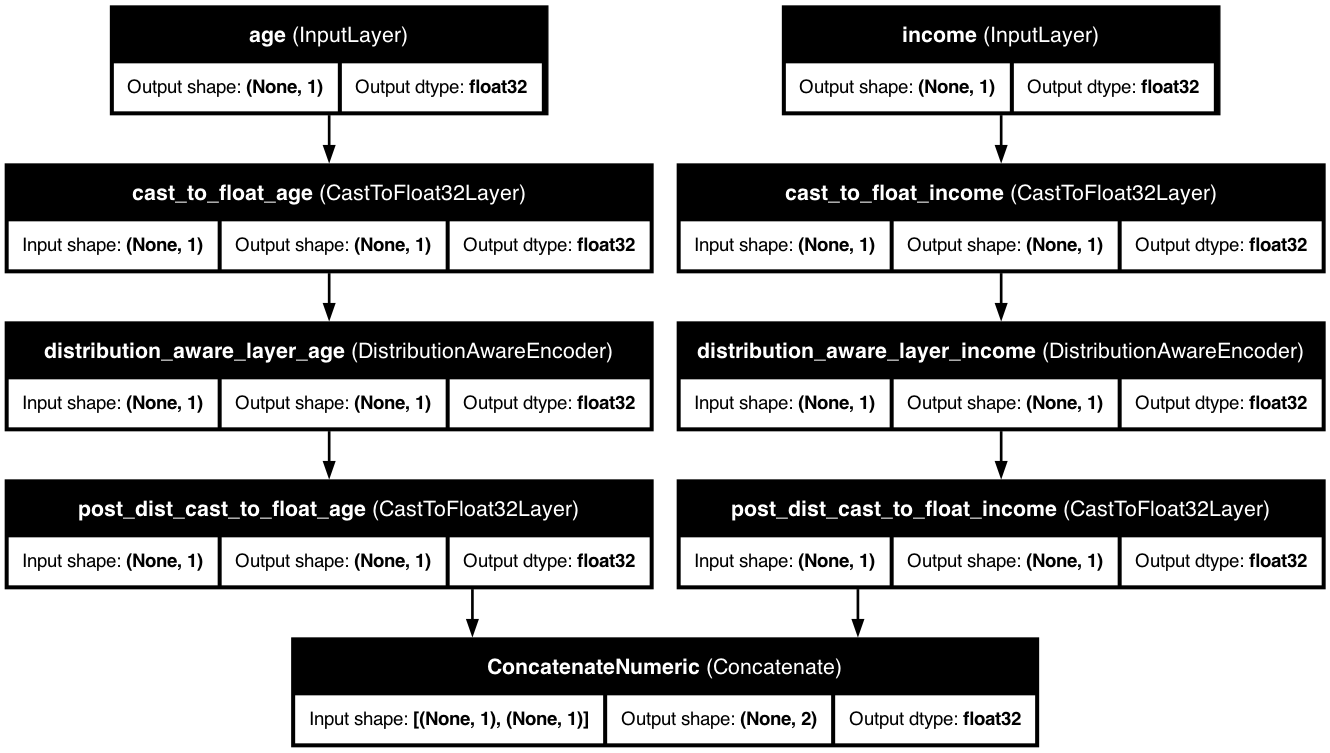
The distribution-aware encoder architecture automatically adapts to your data's distribution, transforming numerical features to better match their underlying statistical properties, improving model performance.