🏗️ KDP Architecture: How the Magic Works
What happens behind the scenes?
Ever wondered what happens when KDP transforms your raw data into ML-ready features? This guide takes you under the hood.
📋 Quick Overview
KDP's architecture consists of interconnected components that work together to make preprocessing faster, smarter, and more efficient. This guide will walk you through each component and show you how they transform raw data into powerful ML features.
🧩 KDP's Building Blocks
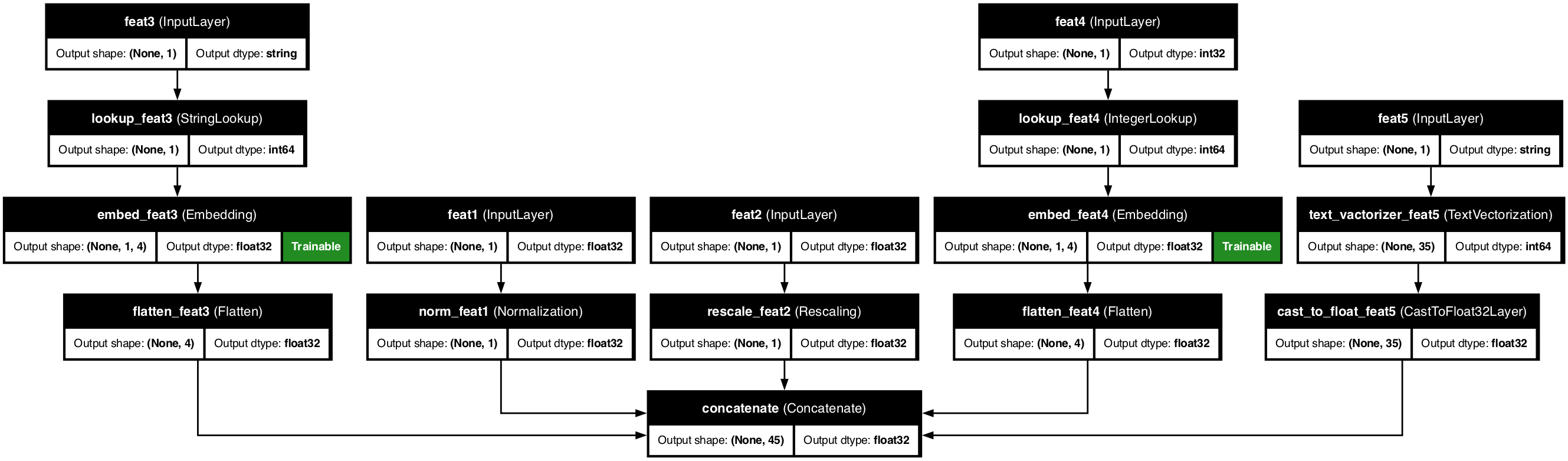
KDP operates like a high-performance factory with specialized stations:
Feature Definition Layer
Where you describe your data
Smart Processors
Specialized handlers for each data type
Advanced Processing Modules
Deep learning enhancements
Combination Engine
Brings everything together
Deployment Bridge
Connects to your ML pipeline
🚀 The Magic in Action
Let's follow the journey of your data through KDP:
1️⃣ Feature Definition: Tell KDP About Your Data
# This is your blueprint - tell KDP what you're working with
features = {
"age": FeatureType.FLOAT_NORMALIZED, # Simple definition
"income": NumericalFeature( # Detailed configuration
name="income",
feature_type=FeatureType.FLOAT_RESCALED,
use_embedding=True
),
"occupation": FeatureType.STRING_CATEGORICAL,
"purchase_date": FeatureType.DATE
}
# Create your data transformer
preprocessor = PreprocessingModel(
path_data="customer_data.csv",
features_specs=features
)
2️⃣ Smart Processors: Type-Specific Transformation
Each feature gets processed by a specialized component:
| Feature Type | Handled By | What It Does |
|---|---|---|
| 🔢 Numerical | NumericalProcessor |
Normalization, scaling, distribution-aware transformations |
| 🏷️ Categorical | CategoricalProcessor |
Vocabulary creation, embedding generation, encoding |
| 📝 Text | TextProcessor |
Tokenization, n-gram analysis, semantic embedding |
| 📅 Date | DateProcessor |
Component extraction, cyclical encoding, temporal pattern detection |
# Behind the scenes: KDP creates a processor chain
numerical_processor = NumericalProcessor(feature_config)
category_processor = CategoricalProcessor(feature_config)
text_processor = TextProcessor(feature_config)
date_processor = DateProcessor(feature_config)
3️⃣ Advanced Modules: Deep Learning Power
KDP enhances basic processing with deep learning:
Distribution-Aware Encoder
Automatically detects and handles data distributions
Tabular Attention
Learns relationships between features
Feature Selection
Identifies which features matter most
Feature MoE
Applies different processing strategies per feature
# Enable advanced processing in one line each
preprocessor = PreprocessingModel(
features_specs=features,
use_distribution_aware=True, # Smart distribution handling
tabular_attention=True, # Feature relationships
feature_selection_placement="all" # Automatic feature importance
)
4️⃣ Combination Engine: Bringing Features Together
KDP combines all processed features based on your configuration:
Concatenation
Simple joining of features
Weighted Combination
Features weighted by importance
Multi-head Attention
Complex interaction modeling
Transformer Blocks
Advanced feature mixing
5️⃣ Deployment Bridge: Production-Ready
The final component connects your preprocessing to training and inference:
# Build the processing pipeline
result = preprocessor.build_preprocessor()
model = result["model"] # Standard Keras model
# Save for production
preprocessor.save_model("customer_preprocess_model")
# Load anywhere
from kdp import PreprocessingModel
loaded = PreprocessingModel.load_model("customer_preprocess_model")
🧠 Smart Decision Making
KDP makes intelligent decisions at multiple points to optimize your preprocessing pipeline:
🔍 Feature Type Detection
KDP can automatically analyze your data to determine the most appropriate feature types:
# KDP detects the best type when you don't specify
auto_detected_features = {
"mystery_column": None # KDP will analyze and decide
}
# Behind the scenes, KDP:
# 1. Examines sample distribution and uniqueness
# 2. Detects data patterns (numbers, text, dates)
# 3. Recommends optimal encoding strategy
📊 Distribution Detection & Handling
KDP examines the statistical properties of each numerical feature to apply appropriate transformations:
# Enable distribution-aware processing
preprocessor = PreprocessingModel(
features_specs=features,
use_distribution_aware=True,
distribution_aware_bins=1000 # Higher resolution for complex distributions
)
# KDP automatically detects and handles:
# - Normal distributions → Standard scaling
# - Skewed distributions → Log transformations
# - Multimodal distributions → Specialized encoding
# - Outliers → Robust scaling techniques
# - Missing values → Imputation strategies
⚙️ Optimization Strategies
KDP dynamically optimizes preprocessing for both efficiency and effectiveness:
# KDP automatically:
# - Caches intermediate results for faster processing
# - Uses batch processing for memory efficiency
# - Parallelizes operations when possible
# - Reduces dimensionality when beneficial
Processing strategies are determined based on:
- Data size and complexity
- Available computational resources
- Feature interdependencies
- Statistical significance of features
🛑 Edge Case Handling
KDP implements sophisticated handling for challenging data situations:
# KDP handles these edge cases automatically:
preprocessor = PreprocessingModel(
features_specs=features,
# No additional configuration needed!
)
Edge cases managed by KDP include:
- Out-of-vocabulary values in categorical features
- Previously unseen patterns in text data
- Date values outside training range
- Missing values or unexpected nulls
- Extreme outliers in numerical columns
🔄 Adaptive Learning
KDP continually refines its understanding of your data:
# Analyze additional data after initial build
preprocessor.update_statistics(new_data)
# Preprocessor automatically adapts to:
# - Shifting distributions
# - New categorical values
# - Changing relationships between features
This adaptive approach ensures your preprocessing remains optimal even as data evolves over time.