👁️ Tabular Attention
Tabular Attention
Discover hidden relationships in your data with sophisticated attention mechanisms
📋 Overview
Tabular Attention is a powerful feature in KDP that enables your models to automatically discover complex interactions between features in tabular data. Based on attention mechanisms from transformers, it helps your models focus on the most important feature relationships without explicit feature engineering.
Automatic Interaction Discovery
Finds complex feature relationships without manual engineering
Context-Aware Processing
Each feature is processed in the context of other features
Improved Performance
Better predictions through enhanced feature understanding
Flexible Integration
Works seamlessly with other KDP processing techniques
Hierarchical Learning
Captures both low-level and high-level patterns
🚀 Getting Started
from kdp import PreprocessingModel, FeatureType
# Define features
features_specs = {
"age": FeatureType.FLOAT_NORMALIZED,
"income": FeatureType.FLOAT_RESCALED,
"occupation": FeatureType.STRING_CATEGORICAL,
"education": FeatureType.INTEGER_CATEGORICAL
}
# Initialize model with standard tabular attention
preprocessor = PreprocessingModel(
path_data="data/my_data.csv",
features_specs=features_specs,
tabular_attention=True, # Enable tabular attention
tabular_attention_heads=4, # Number of attention heads
tabular_attention_dim=64, # Attention dimension
tabular_attention_dropout=0.1 # Dropout rate
)
🧠 How It Works
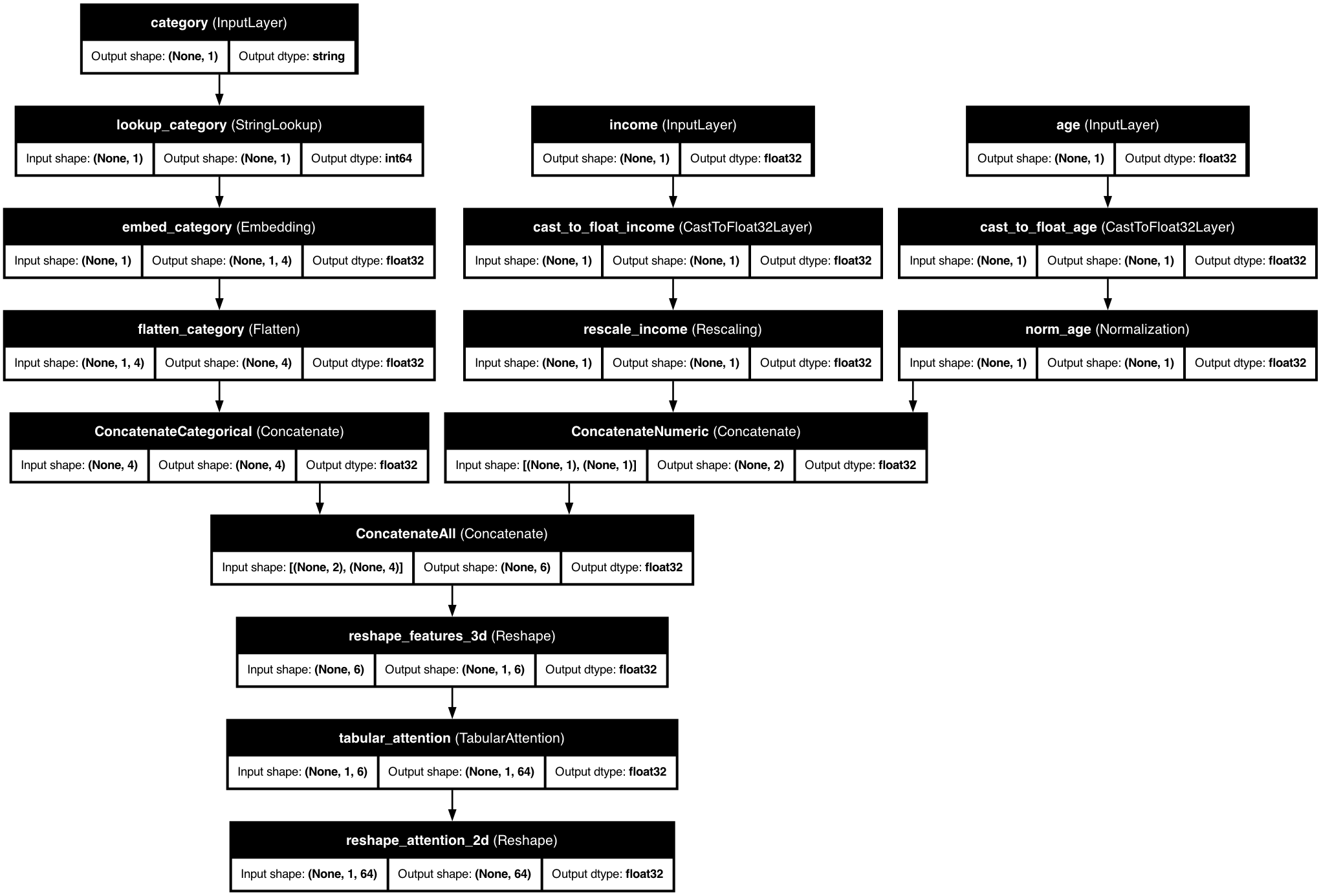
KDP's tabular attention mechanism transforms features through a multi-head attention mechanism, allowing the model to learn complex patterns across features.
Standard Tabular Attention
Inter-Feature Attention
Features attend to each other within each sample, capturing dependencies between different features.
Inter-Sample Attention
Samples attend to each other for each feature, capturing patterns across different samples.
Feed-Forward Networks
Process attended features further with non-linear transformations.
Multi-Resolution Tabular Attention
Specialized Processing
Numerical and categorical features processed through type-specific attention mechanisms.
Cross-Attention
Enables features to attend across different types, capturing complex interactions.
Type-Specific Projections
Each feature type gets custom embedding dimensions for optimal representation.
📊 Model Architecture
KDP's tabular attention mechanism:
The diagram shows how tabular attention transforms features through a multi-head attention mechanism, allowing the model to learn complex patterns across features.
💡 How to Enable
⚙️ Configuration Options
General Options
| Parameter | Type | Default | Description |
|---|---|---|---|
tabular_attention |
bool | False | Enable/disable attention mechanisms |
tabular_attention_heads |
int | 4 | Number of attention heads |
tabular_attention_dim |
int | 64 | Dimension of the attention model |
tabular_attention_dropout |
float | 0.1 | Dropout rate for regularization |
Multi-Resolution Options
| Parameter | Type | Default | Description |
|---|---|---|---|
tabular_attention_embedding_dim |
int | 32 | Dimension for categorical embeddings |
tabular_attention_placement |
str | "ALL_FEATURES" | Where to apply attention |
Placement Options
| Option | Description | Best For |
|---|---|---|
ALL_FEATURES |
Apply to all features uniformly | General purpose, balanced datasets |
NUMERIC |
Only numerical features | Datasets dominated by numerical features |
CATEGORICAL |
Only categorical features | Datasets with important categorical relationships |
MULTI_RESOLUTION |
Type-specific attention | Mixed data types with different importance |
🎯 Best Use Cases
When to Use Standard Tabular Attention
- When your features are mostly of the same type
- When you have a balanced mix of numerical and categorical features
- When feature interactions are likely uniform across feature types
- When computational efficiency is a priority
When to Use Multi-Resolution Attention
- When you have distinctly different numerical and categorical features
- When categorical features need special handling (high cardinality)
- When feature interactions between types are expected to be important
- When certain feature types dominate your dataset
🔍 Examples
Customer Analytics with Standard Attention
from kdp import PreprocessingModel, FeatureType
from kdp.enums import TabularAttentionPlacementOptions
features_specs = {
"customer_age": FeatureType.FLOAT_NORMALIZED,
"account_age": FeatureType.FLOAT_NORMALIZED,
"avg_purchase": FeatureType.FLOAT_RESCALED,
"total_orders": FeatureType.FLOAT_RESCALED,
"customer_type": FeatureType.STRING_CATEGORICAL,
"region": FeatureType.STRING_CATEGORICAL
}
preprocessor = PreprocessingModel(
path_data="data/customer_data.csv",
features_specs=features_specs,
tabular_attention=True,
tabular_attention_heads=4,
tabular_attention_dim=64,
tabular_attention_dropout=0.1,
tabular_attention_placement=TabularAttentionPlacementOptions.ALL_FEATURES.value
)
Product Recommendations with Multi-Resolution Attention
from kdp import PreprocessingModel, FeatureType
from kdp.enums import TabularAttentionPlacementOptions
features_specs = {
# Numerical features
"user_age": FeatureType.FLOAT_NORMALIZED,
"days_since_last_purchase": FeatureType.FLOAT_RESCALED,
"avg_session_duration": FeatureType.FLOAT_NORMALIZED,
"total_spend": FeatureType.FLOAT_RESCALED,
"items_viewed": FeatureType.FLOAT_RESCALED,
# Categorical features
"gender": FeatureType.STRING_CATEGORICAL,
"product_category": FeatureType.STRING_CATEGORICAL,
"device_type": FeatureType.STRING_CATEGORICAL,
"subscription_tier": FeatureType.INTEGER_CATEGORICAL,
"day_of_week": FeatureType.INTEGER_CATEGORICAL
}
preprocessor = PreprocessingModel(
path_data="data/recommendation_data.csv",
features_specs=features_specs,
tabular_attention=True,
tabular_attention_heads=8, # More heads for complex interactions
tabular_attention_dim=128, # Larger dimension for rich representations
tabular_attention_dropout=0.15, # Slightly higher dropout for regularization
tabular_attention_embedding_dim=64, # Larger embedding for categorical features
tabular_attention_placement=TabularAttentionPlacementOptions.MULTI_RESOLUTION.value
)
📊 Performance Considerations
Memory Usage
- Standard Attention: O(n²) memory complexity for n features
- Multi-Resolution: O(n_num² + n_cat²) memory complexity
- For large feature sets, multi-resolution is more efficient
Computational Cost
- Attention mechanisms introduce additional training time
- Multi-head attention scales linearly with number of heads
- Multi-resolution can be faster when categorical features dominate
Guidelines:
| Dataset Size | Attention Type | Recommended Heads | Dimension |
|---|---|---|---|
| Small (<10K) | Standard | 2-4 | 32-64 |
| Medium | Standard/Multi-Resolution | 4-8 | 64-128 |
| Large (>100K) | Multi-Resolution | 8-16 | 128-256 |
💡 Pro Tips
Head Count Selection
Start with 4 heads for most problems, increase for complex feature interactions, but beware of overfitting with too many heads.
Dimension Tuning
Choose dimensions divisible by number of heads, larger for complex patterns, but balance with dataset size to avoid overfitting.
Placement Strategy
Use ALL_FEATURES for initial experimentation, MULTI_RESOLUTION for mixed data types, and NUMERIC/CATEGORICAL for targeted focus.