🧩 Feature-wise Mixture of Experts
Feature-wise Mixture of Experts (MoE)
Specialized processing for heterogeneous tabular features
📋 Overview
Feature-wise Mixture of Experts (MoE) is a powerful technique that applies different processing strategies to different features based on their characteristics. This approach allows for more specialized handling of each feature, improving model performance on complex, heterogeneous datasets.
🚀 Basic Usage
from kdp import PreprocessingModel, FeatureType
# Define features
features = {
"age": FeatureType.FLOAT_NORMALIZED,
"income": FeatureType.FLOAT_RESCALED,
"occupation": FeatureType.STRING_CATEGORICAL,
"purchase_history": FeatureType.FLOAT_ARRAY,
}
# Create preprocessor with Feature MoE
preprocessor = PreprocessingModel(
path_data="data.csv",
features_specs=features,
use_feature_moe=True, # Turn on the magic
feature_moe_num_experts=4, # Four specialized experts
feature_moe_expert_dim=64 # Size of expert representations
)
# Build and use
result = preprocessor.build_preprocessor()
model = result["model"]
🧩 How Feature MoE Works
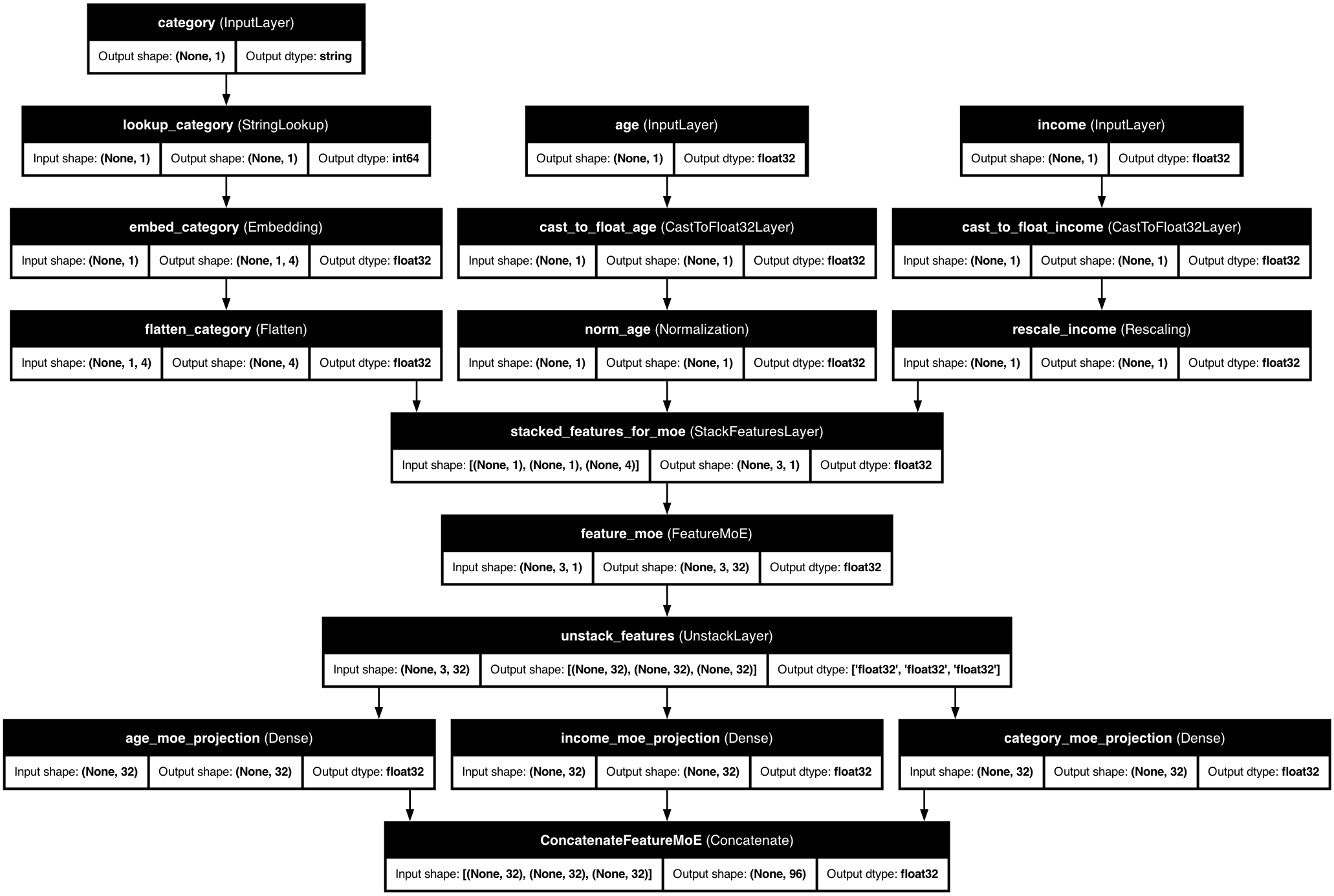
KDP's Feature MoE uses a "divide and conquer" approach with smart routing: each expert is a specialized neural network, a router determines which experts should process each feature, features can use multiple experts with different weights, and residual connections preserve original feature information.
⚙️ Configuration Options
| Parameter | Description | Default | Recommended Range |
|---|---|---|---|
feature_moe_num_experts |
Number of specialists | 4 | 3-5 for most tasks, 6-8 for very complex data |
feature_moe_expert_dim |
Size of expert output | 64 | Larger (96-128) for complex patterns |
feature_moe_routing |
How to assign experts | "learned" | "learned" for automatic, "predefined" for control |
feature_moe_sparsity |
Use only top k experts | 2 | 1-3 (lower = faster, higher = more accurate) |
feature_moe_hidden_dims |
Expert network size | [64, 32] | Deeper for complex relationships |
💡 Pro Tips for Feature MoE
Group Similar Features
Assign related features to the same expert for consistent processing, like grouping demographic, financial, product, and temporal features to different experts.
Visualize Expert Assignments
Examine which experts handle which features by plotting the assignments as a heatmap to understand your model's internal decisions.
Progressive Training
Start with frozen experts, then fine-tune to allow the model to learn basic patterns before specializing.
🔍 When to Use Feature MoE
Heterogeneous Features
When your features have very different statistical properties (categorical, text, numerical, temporal).
Complex Multi-Modal Data
When features come from different sources or modalities (user features, item features, interaction features).
Transfer Learning
When adapting a model to new features with domain-specific experts for different feature groups.