🔢 Advanced Numerical Embeddings
Transform raw numerical features into powerful representations
Enhance your model's ability to learn from numerical data with KDP's sophisticated dual-branch embedding architecture.
📋 Architecture Overview
Advanced Numerical Embeddings in KDP transform continuous values into meaningful embeddings using a dual-branch architecture:
Continuous Branch
Processes raw values through a small MLP for smooth pattern learning
Discrete Branch
Discretizes values into learnable bins with trainable boundaries
The outputs from both branches are combined using a learnable gate mechanism, providing the perfect balance between continuous and discrete representations.
✨ Key Benefits
Dual-Branch Architecture
Combines the best of both continuous and discrete processing
Learnable Boundaries
Adapts bin edges during training for optimal discretization
Feature-Specific Processing
Each feature gets its own specialized embedding
Memory Efficient
Optimized for handling large-scale tabular datasets
Flexible Integration
Works seamlessly with other KDP features
Residual Connections
Ensures stability during training
🚀 Getting Started
Basic Usage
from kdp import PreprocessingModel, FeatureType
# Define numerical features
features_specs = {
"age": FeatureType.FLOAT_NORMALIZED,
"income": FeatureType.FLOAT_RESCALED,
"credit_score": FeatureType.FLOAT_NORMALIZED
}
# Initialize model with numerical embeddings
preprocessor = PreprocessingModel(
path_data="data/my_data.csv",
features_specs=features_specs,
use_numerical_embedding=True, # Enable numerical embeddings
numerical_embedding_dim=8, # Size of each feature's embedding
numerical_num_bins=10 # Number of bins for discretization
)
Advanced Configuration
from kdp import PreprocessingModel
from kdp.features import NumericalFeature
from kdp.enums import FeatureType
# Define numerical features with customized embeddings
features_specs = {
"age": NumericalFeature(
name="age",
feature_type=FeatureType.FLOAT_NORMALIZED,
use_embedding=True,
embedding_dim=8,
num_bins=10,
init_min=18, # Domain-specific minimum
init_max=90 # Domain-specific maximum
),
"income": NumericalFeature(
name="income",
feature_type=FeatureType.FLOAT_RESCALED,
use_embedding=True,
embedding_dim=12,
num_bins=15,
init_min=0, # Cannot be negative
init_max=500000 # Maximum expected
)
}
# Create preprocessing model
preprocessor = PreprocessingModel(
path_data="data/my_data.csv",
features_specs=features_specs,
use_numerical_embedding=True,
numerical_mlp_hidden_units=16, # Hidden layer size for continuous branch
numerical_dropout_rate=0.1, # Regularization
numerical_use_batch_norm=True # Normalize activations
)
🧠 How It Works
Individual Feature Embeddings (NumericalEmbedding)
The NumericalEmbedding layer processes each numerical feature through two parallel branches:
- Continuous Branch:
- Processes each feature through a small MLP
- Applies dropout and optional batch normalization
-
Includes a residual connection for stability
-
Discrete Branch:
- Maps each value to a bin using learnable min/max boundaries
- Retrieves a learned embedding for each bin
-
Captures non-linear and discrete patterns
-
Learnable Gate:
- Combines outputs from both branches using a sigmoid gate
- Adaptively weights continuous vs. discrete representations
- Learns optimal combination per feature and dimension
Input value
┌────────┐ ┌────────┐
│ MLP │ │Binning │
└────────┘ └────────┘
│ │
▼ ▼
Continuous Discrete
Embedding Embedding
│ │
└─────┬───────┘
│
▼
Gating Mechanism
│
▼
Final Embedding
Global Feature Embeddings (GlobalNumericalEmbedding)
The GlobalNumericalEmbedding layer processes all numerical features together and returns a single compact representation:
- Flattens input features (if needed)
- Applies
NumericalEmbeddingto process all features - Performs global pooling (average or max) across feature dimensions
- Returns a single vector representing all numerical features
This approach is ideal for: - Processing large feature sets efficiently - Capturing cross-feature interactions - Reducing dimensionality of numerical data - Learning a unified numerical representation
⚙️ Configuration Options
Individual Embeddings
| Parameter | Type | Default | Description |
|---|---|---|---|
use_numerical_embedding |
bool | False | Enable numerical embeddings |
numerical_embedding_dim |
int | 8 | Size of each feature's embedding |
numerical_mlp_hidden_units |
int | 16 | Hidden layer size for continuous branch |
numerical_num_bins |
int | 10 | Number of bins for discretization |
numerical_init_min |
float/list | -3.0 | Initial minimum for scaling |
numerical_init_max |
float/list | 3.0 | Initial maximum for scaling |
numerical_dropout_rate |
float | 0.1 | Dropout rate for regularization |
numerical_use_batch_norm |
bool | True | Apply batch normalization |
Global Embeddings
| Parameter | Type | Default | Description |
|---|---|---|---|
use_global_numerical_embedding |
bool | False | Enable global numerical embeddings |
global_embedding_dim |
int | 8 | Size of global embedding |
global_mlp_hidden_units |
int | 16 | Hidden layer size for continuous branch |
global_num_bins |
int | 10 | Number of bins for discretization |
global_init_min |
float/list | -3.0 | Initial minimum for scaling |
global_init_max |
float/list | 3.0 | Initial maximum for scaling |
global_dropout_rate |
float | 0.1 | Dropout rate for regularization |
global_use_batch_norm |
bool | True | Apply batch normalization |
global_pooling |
str | "average" | Pooling method ("average" or "max") |
🎯 Best Use Cases
When to Use Individual Embeddings
- When each numerical feature conveys distinct information
- When features have different scales or distributions
- When you need fine-grained control of each feature's representation
- When memory usage is a concern (more efficient with many features)
- For explainability (each feature has its own embedding)
When to Use Global Embeddings
- When you have many numerical features
- When features have strong interdependencies
- When dimensionality reduction is desired
- When a unified representation of all numerical data is needed
- For simpler model architectures (single vector output)
🔍 Examples
Financial Risk Modeling
from kdp import PreprocessingModel
from kdp.features import NumericalFeature
from kdp.enums import FeatureType
# Define financial features with domain knowledge
features_specs = {
"income": NumericalFeature(
name="income",
feature_type=FeatureType.FLOAT_RESCALED,
use_embedding=True,
embedding_dim=8,
num_bins=15,
init_min=0,
init_max=1000000
),
"debt_ratio": NumericalFeature(
name="debt_ratio",
feature_type=FeatureType.FLOAT_NORMALIZED,
use_embedding=True,
embedding_dim=4,
num_bins=8,
init_min=0,
init_max=1 # Ratio typically between 0-1
),
"credit_score": NumericalFeature(
name="credit_score",
feature_type=FeatureType.FLOAT_NORMALIZED,
use_embedding=True,
embedding_dim=6,
num_bins=10,
init_min=300,
init_max=850 # Standard credit score range
),
"payment_history": NumericalFeature(
name="payment_history",
feature_type=FeatureType.FLOAT_NORMALIZED,
use_embedding=True,
embedding_dim=8,
num_bins=5,
init_min=0,
init_max=1 # Simplified score between 0-1
)
}
# Create preprocessing model
preprocessor = PreprocessingModel(
path_data="data/financial_data.csv",
features_specs=features_specs,
use_numerical_embedding=True,
numerical_mlp_hidden_units=16,
numerical_dropout_rate=0.2, # Higher dropout for financial data
numerical_use_batch_norm=True
)
Healthcare Patient Analysis
from kdp import PreprocessingModel
from kdp.features import NumericalFeature
from kdp.enums import FeatureType
# Define patient features
features_specs = {
# Define many health metrics
"age": NumericalFeature(...),
"bmi": NumericalFeature(...),
"blood_pressure": NumericalFeature(...),
"cholesterol": NumericalFeature(...),
"glucose": NumericalFeature(...),
# Many more metrics...
}
# Use global embedding to handle many numerical features
preprocessor = PreprocessingModel(
path_data="data/patient_data.csv",
features_specs=features_specs,
use_global_numerical_embedding=True, # Process all features together
global_embedding_dim=32, # Higher dimension for complex data
global_mlp_hidden_units=64,
global_num_bins=20, # More bins for medical precision
global_dropout_rate=0.1,
global_use_batch_norm=True,
global_pooling="max" # Use max pooling to capture extremes
)
💡 Pro Tips
- Choose the Right Embedding Type
- Use individual embeddings for interpretability and precise control
-
Use global embeddings for efficiency with many numerical features
-
Distribution-Aware Initialization
- Set
init_minandinit_maxbased on your data's actual distribution - Use domain knowledge to set meaningful boundary points
-
Initialize closer to anticipated feature range for faster convergence
-
Dimensionality Guidelines
- Start with
embedding_dim= 4-8 for simple features - Use 8-16 for complex features with non-linear patterns
-
For global embeddings, scale with the number of features (16-64)
-
Performance Tuning
- Increase
num_binsfor more granular discrete representations - Adjust
mlp_hidden_unitsto 2-4x the embedding dimension - Use batch normalization for faster, more stable training
-
Adjust dropout based on dataset size (higher for small datasets)
-
Combine with Other KDP Features
- Pair with distribution-aware encoding for optimal numerical handling
- Use with tabular attention to learn cross-feature interactions
- Combine with feature selection for automatic dimensionality reduction
🔗 Related Topics
📊 Model Architecture
Advanced numerical embeddings transform your numerical features into rich representations:
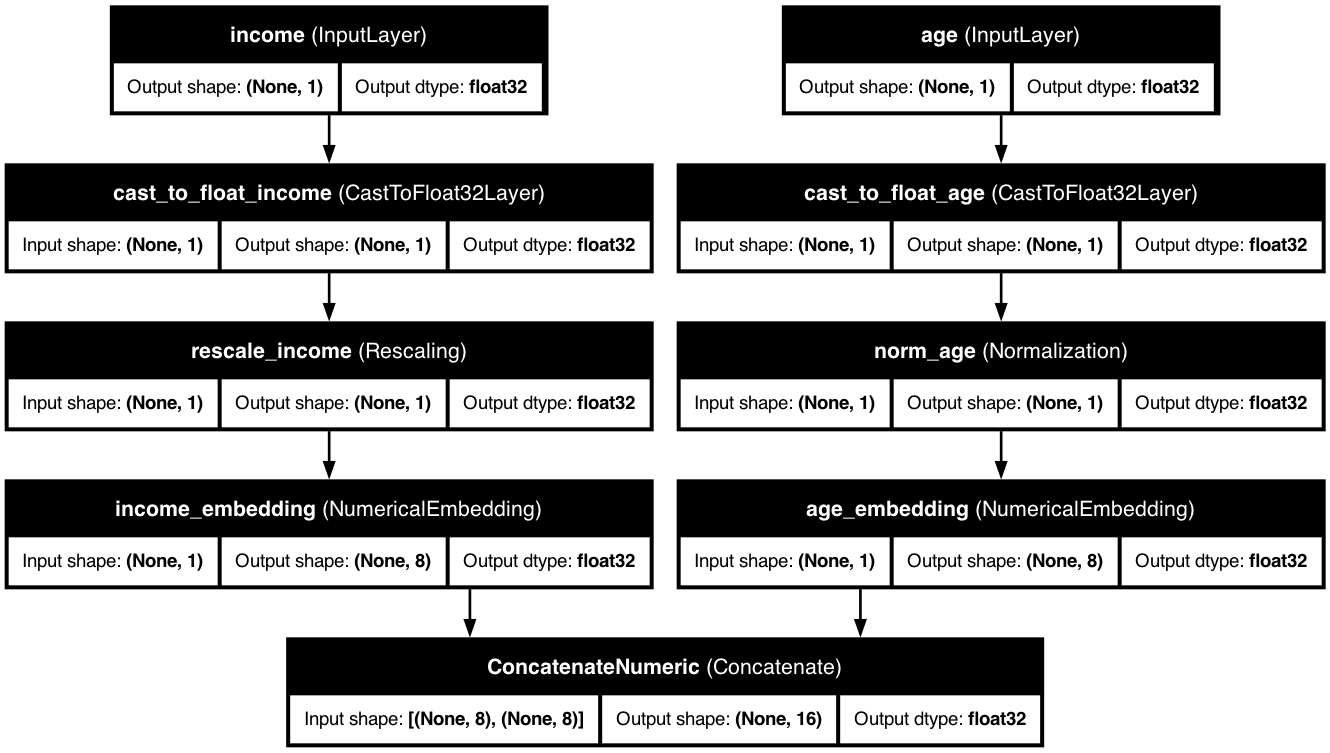
Global numerical embeddings allow coordinated embeddings across all features:
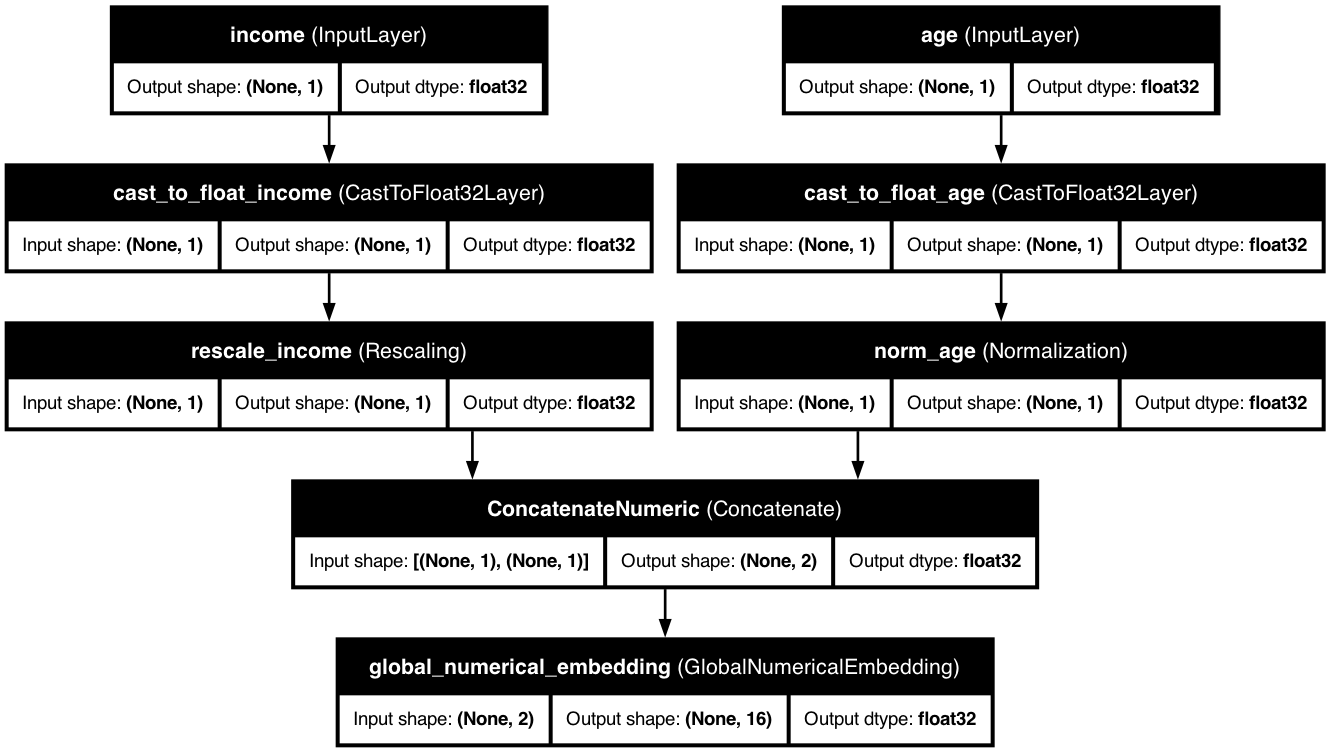
These diagrams illustrate how KDP transforms numerical features into rich embedding spaces, capturing complex patterns and non-linear relationships.
💡 How to Enable
🧩 Dependencies
Core Dependencies
- 🐍 Python 3.9+
- 🔄 TensorFlow 2.18.0+
- 🔢 NumPy 1.22.0+
- 📊 Pandas 2.2.0+
- 📝 loguru 0.7.2+
Optional Dependencies
| Package | Purpose | Install Command |
|---|---|---|
| scipy | 🧪 Scientific computing and statistical functions | pip install "kdp[dev]" |
| ipython | 🔍 Interactive Python shell and notebook support | pip install "kdp[dev]" |
| pytest | ✅ Testing framework and utilities | pip install "kdp[dev]" |
| pydot | 📊 Graph visualization for model architecture | pip install "kdp[dev]" |
| Development Tools | 🛠️ All development dependencies | pip install "kdp[dev]" |
| Documentation Tools | 📚 Documentation generation tools | pip install "kdp[doc]" |